In an attempt to make my artifacts smaller, I recently chose to use 7-Zip compression, or archiveType: 7z, in an Archive Files task of an Azure DevOps YAML pipeline. 7-Zip provides 5 compression levels: 1 (fastest), 3 (fast), 5 (normal), 7 (maximum) and 9 (ultra), as well as option 0, which doesn’t compress anything.
I like YAML pipelines, because they live in my repo and I can use templates. However, the online editing experience is not particularly great.
About a month ago I saw the trailer for Tim Burton’s upcoming movie Miss Peregrine’s Home for Peculiar Children and it immediately caught my attention. It turns out it’s originally a book, so I went over to Amazon, downloaded the first few pages and ended up buying the whole thing. It’s exactly the kind of fantastic universe I like to immerse myself into.
The Kindle version that I bought included three novels actually: Miss Peregrine’s Home for Peculiar Children and its two sequels, Hollow City and Library of Souls.
Modern Americans often assume that multilingualism should be discouraged, because it is supposed to hinder child language acquisition and immigrant assimilation.
— Jared Diamond, The World Until Yesterday: What Can We Learn from Traditional Societies?
And to think that these people effectively rule the world…
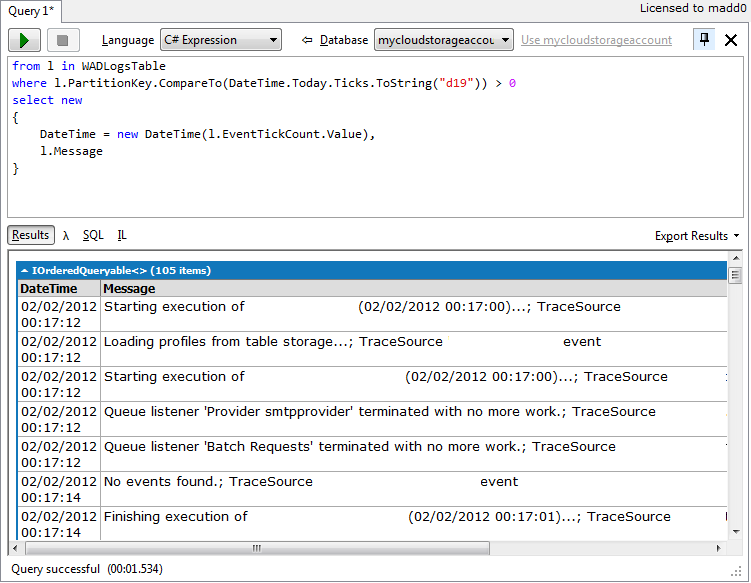
If you are using Windows Azure Diagnostics with the DiagnosticMonitorTraceListener you will most likely have a table in your storage account called WADLogsTable with a ton of data in it. It can be a bit overwhelming.
A colleague and I wanted to get two simple pieces of information: an event’s date and the corresponding message. Furthermore, we only wanted events that had happened today. Here’s what we came up with using LINQPad and the Azure Storage Driver.
I promise, this is the last you will see on this subject today (from my part, anyway). It’s for those who were not online yesterday and/or are in a different time zone and/or didn’t see my post from yesterday and/or don’t speak French.
Azure Storage Explorer I’ve been working quite a bit with Windows Azure lately and particularly with Table Storage. I used to use SQL Server Mangement Studio to work with SQL Server and I found Azure Storage Explorer (screenshot on the left), which is actually pretty good for working with all three storage options: queues, tables and blobs.
I stumbled upon an interesting question on StackOverflow where someone is using a series of TextBlocks in a StackPanel to show them side by side and would like part of the displayed text to be coloured with one colour and the rest with another.
There has got to be a thousand ways to do this, but it got me thinking of how I would do it, and especially, how to do it quickly because I have a job besides StackOverflow Here’s my take on the problem.
What’s in a name? That which we call a rose By any other name would smell as sweet.
— Romeo and Juliet (II, ii, 1-2)
This morning I learnt through Engadget that what was known until now as Project Natal is now called Kinect for Xbox 360, as revealed just before E3 by none other than a 76-person cast of Cirque du Soleil. I had two reactions:
Why wasn’t I invited?
For those of you who really appreciate the time gained by not moving your hand away from your keyboard and towards the mouse, Microsoft released 4 keybinding reference cards (cheet sheets if you will) for Visual Studio 2010 in the form of high-quality PDFs.
In these foldable cards you’ll find the default keyboard shortcuts for:
Visual Basic .NET Visual C++ Visual C# Visual F# Available on MSDN Downloads.
Comments: montana - May 5, 2010